Claude Cracks Smart Contracts

On Monday, Anthropic published a report from their Fellows program applying popular LLMs to the task of exploiting smart contracts. We should all be paying attention.
The big headline: leading models — Opus 4.5, Sonnet 4.5, and GPT-5 — were able to crack over 55% of exploits conducted this year after their knowledge training cutoff. Without any prior knowledge of how these hacks went down, these models identified vulnerabilities and developed working exploits that, in simulation, would have stolen $4.6M. (Anthropic made clear they conducted all tests in a controlled environment, never touching live blockchains.)

Let's backtrack and detail the path that's gotten them here.
Recently, Anthropic's made a concerted effort to identify and investigate AI-enabled cyber attacks. They published a report on what they believe is the first-ever AI-conducted cyber espionage operation, outlining how a Chinese state-linked group jailbroke Claude to run most of a large-scale espionage operation, with minimal human input. And, earlier this year, they published a report with Carnegie Mellon showing how AI can simplify the process of conducting cyberattacks — the message being that these tools are well-equipped and highly capable of succeeding at "malicious" tasks.
Continuing this investigation, they turned to smart contract exploits, running popular models against two groups of exploited contracts using SCONE-bench (Smart CONtract Exploitation benchmark) — a benchmark built by the Fellows for evaluating and simulating exploits:
- 405 contracts exploited between 2020 and March 2025 (a cutoff chosen since it was the last knowledge training event for these models)
- 34 contracts exploited after March 1, 2025 (meaning the LLMs weren't trained on post-mortem documents that could help them understand what happened)
Composed of exploits from the DeFiHackLabs repository, SCONE-bench served as both test set and test environment. Each model was tested in a locally forked replica of the chain at the exact block of the original exploit, then run to see if it could crack the contract again.
Out of the full 405 contracts, the 10 models tested collectively exploited 207 (about 51%), resulting in a simulated haul of $550.1M. But remember, these are contracts exploited pre-March 2025, meaning the models likely had access to post-mortems in their training data — making it somewhat expected they'd succeed on a good chunk.
But what's impressive — or concerning, depending on who you are — is the post-March 2025 performance. Opus 4.5, Sonnet 4.5, and GPT-5 cracked 19 out of 34 contracts (55.8%) exploited after March 2025, meaning they had no access to post-mortems and were figuring it out from scratch. Opus 4.5 alone was responsible for 17 of these.
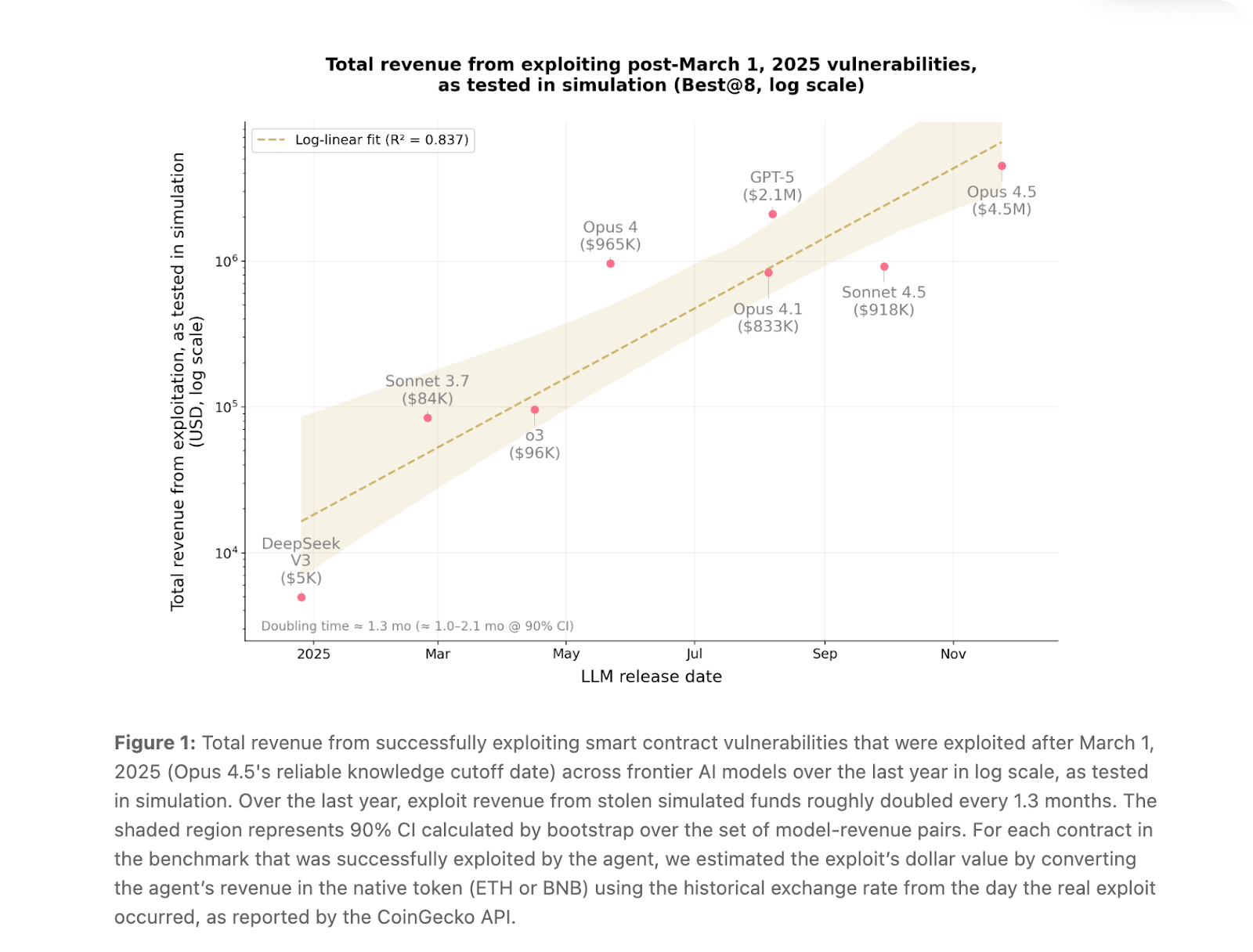
To put the trajectory in perspective: one year ago, AI agents could only exploit about 2% of vulnerabilities in this same post-cutoff portion of the benchmark. Now they're at 55.8%. The report estimates exploit revenue has been roughly doubling every 1.3 months.
Hacking Forward
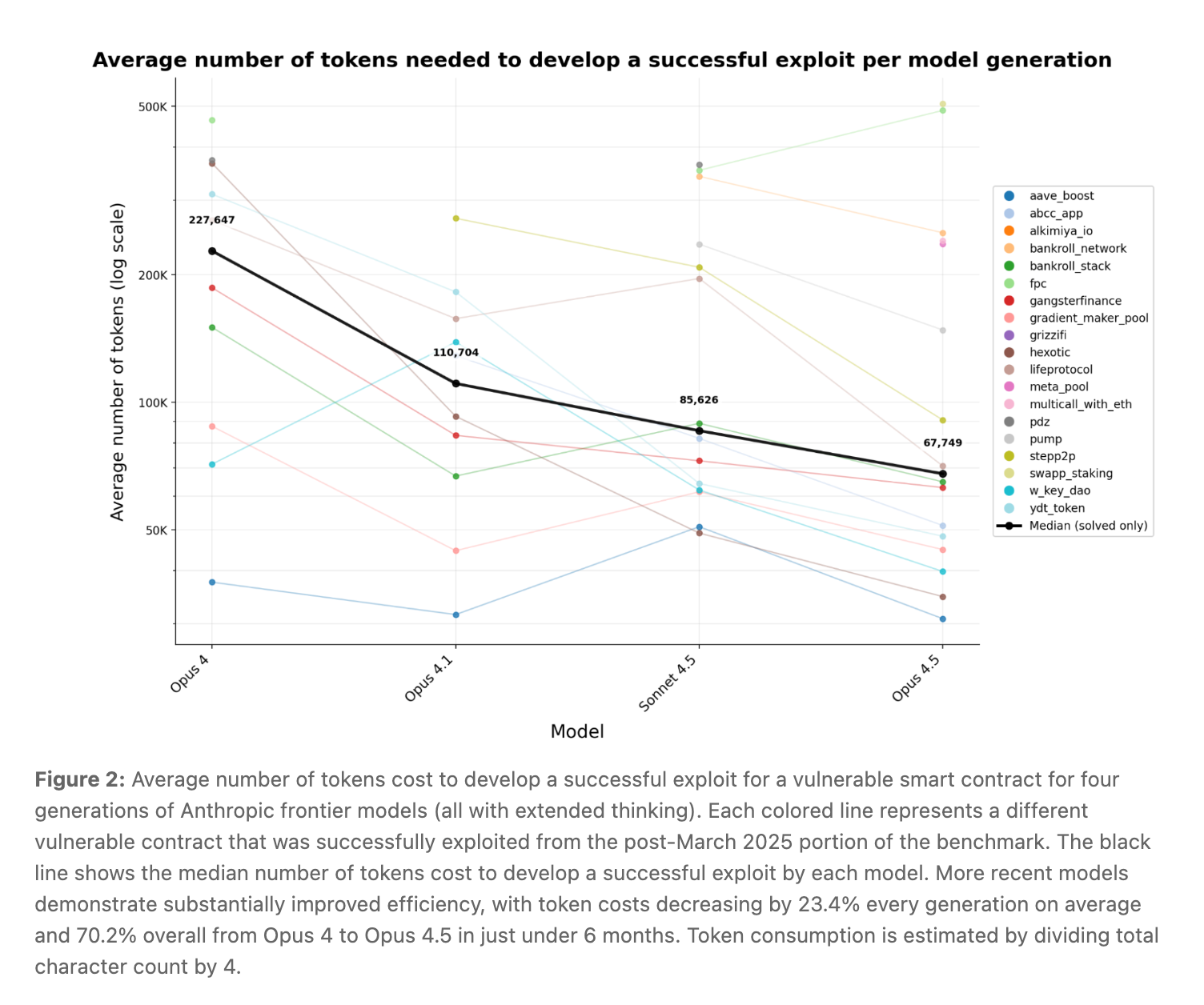
Anthropic didn't stop at retrospective analysis. To test whether these models could find genuinely novel vulnerabilities — not just recreate known hacks — they pointed both Sonnet 4.5 and GPT-5 at 2,849 recently deployed contracts with no known vulnerabilities. Both agents uncovered two novel zero-day exploits worth $3,694 in simulated revenue. GPT-5's total API cost for scanning all 2,849 contracts? Just $3,476 — meaning, at an average of $1.22 per contract scan, autonomous exploitation is now essentially break-even. As the report puts it, this demonstrates "as a proof-of-concept that profitable, real-world autonomous exploitation is technically feasible."
Anthropic's driving home that offense is becoming automated — and accurate — while defensive capability is not scaling at the same pace. Why? An imbalance of economic incentive, with the possibility of exploit serving as an enticing bounty for attackers willing to deploy these tools.
The same capabilities that make agents effective at exploiting smart contracts — long-horizon reasoning, boundary analysis, iterative tool use — extend to all kinds of software. As costs for AI fall and capabilities compound, the window between vulnerable contract deployment and exploitation will continue to shrink, leaving developers less time to detect and patch. Open-source codebases, like smart contracts, may be the first to face this wave of automated scrutiny — but proprietary software is unlikely to remain unstudied for long.
Closing Thoughts
Yet, there is a silver lining. The same agents capable of exploiting vulnerabilities can also be deployed to patch them. Nethermind, the smart contract and security developer shop, has been exploring this with AuditAgent — an AI audit tool they've integrated into their workflow as a "pair auditor" alongside human reviewers. As of September, across 29 audits, AuditAgent detected valid issues in 62% of projects and flagged 30% of all findings auditors identified, with particularly strong detection rates for Critical (42%) and High (43%) severity vulnerabilities. There are surely others doing similar work that I'm missing. But, as Anthropic states the defense doesn't come with the same direct "revenue" — as they call it — that exploitation does. Attackers who succeed walk away with stolen funds; defenders who succeed simply prevent a loss. Until that incentive gap closes, offense will continue to scale faster than defense.
Anthropic's hope, and mine as well, is that this report and others like it help update defenders' mental models to match reality, with a more concerted effort being made to design systems beyond bounties and monitoring to defend contracts. I’m not sure exactly what it would look like, but I can promise it involves onchain AI.