AI Prediction Arbiters?


View in Browser
Sponsor: Bitget — New ATH for Gold! Trade gold, silver, and more directly on Bitget.
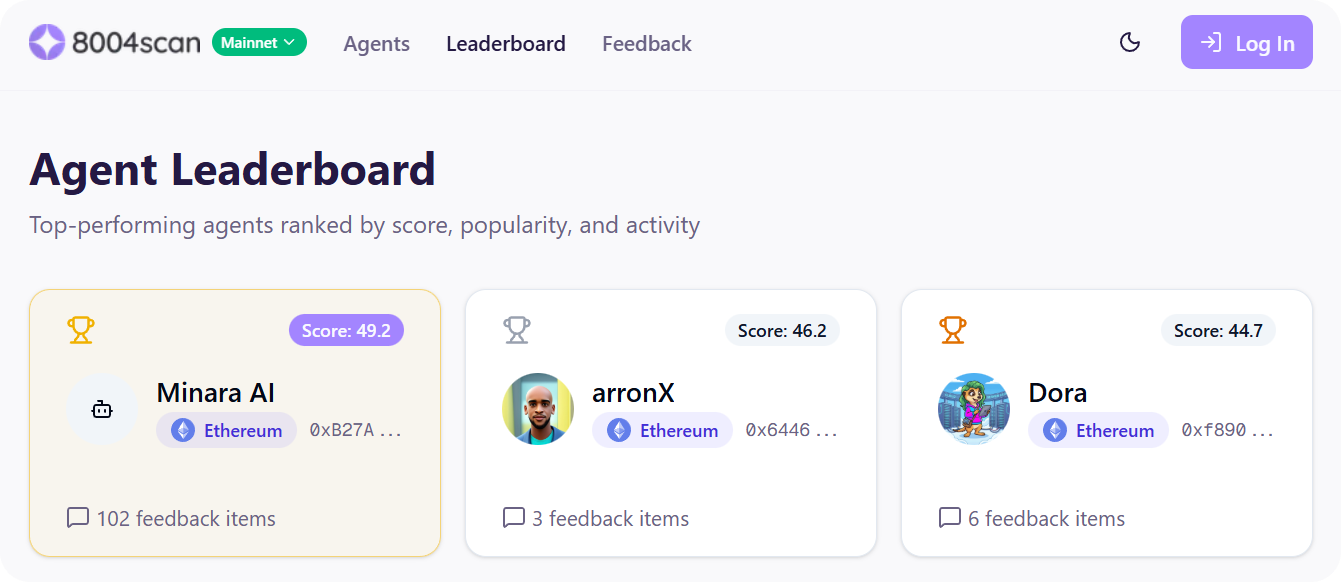
At long last, ERC-8004 launched Thursday, bringing onchain identity and reputation infrastructure to the agentic economy.
The standard solves two core problems: without verifiable identity, bad actors spin up agents, extract value, and disappear; without portable reputation, good agents start from zero every time they enter a new market.
ERC-8004 looks to address these challenges through three onchain registries:
- Identity Registry gives every agent a unique onchain identity as an ERC-721 token. The identity includes a registration file declaring capabilities, communication endpoints, and supported trust models.
- Reputation Registry tracks cryptographically verified feedback from clients. Before leaving a review, clients must obtain signed authorization from the agent to prevent spam. Scores live onchain and are queryable by other smart contracts — i.e. a service contract could check that an agent's score exceeds a threshold before accepting a bid (8004scan has done a great job of indexing these scores and making them discoverable).
- Validation Registry coordinates third-party verification of agent work. Note: this registry's specification is still under active discussion and isn't live at launch.
Connect these to x402 for payments and protocols like A2A and MCP for communication, and you have a complete stack for agent-to-agent economic activity.
The Ethereum Foundation’s dAI team recently published an ecosystem map for teams building with 8004 but, if I’m going to call one out specifically that’s worth tracking, I’d highlight Daydreams, which released the Lucid Agents Commerce SDK for building 8004-enabled agents. They've also been building some pretty standout x402 agents, useful for actual, everyday activities like discovering books, tracking U.S. treasury data, or tennis stats.
There aren't many agents live yet, but keep an eye on 8004scan’s searchable directory, as it offers a great outlet for agent discovery as more of them do come online.

Last week, a16z published a proposal for using LLMs as prediction market judges.
The pitch is to lock a specific model and prompt into the blockchain at a market's contract creation, let traders inspect the resolution's nuance before betting, then run it at resolution. The goal here is to eliminate human bias and problems that can arise from token-based dispute resolution.
There's just one problem the proposal glosses over: LLMs aren't designed to give the same answer twice.

The Resolution Bottleneck
Resolution has become the chokepoint for prediction markets at scale.
In their article, a16z cites multiple markets where resolution devolved into scandal:
- The Venezuela election market, which saw over $6M in volume, before devolving into accusations of biased resolution when observers alleged fraud and the government declared the opposite result.
- The Zelensky suit market, which attracted $200M in bets on whether Ukraine's president would wear a suit to a NATO summit. During the market's resolution, UMA token holders flipped the resolution from "Yes" to "No" despite news coverage describing his attire as a suit, leading to traders crying foul and heated discussion over what classifies as a "suit".
- a Ukraine territorial control contract specified resolution based on a particular online map; someone allegedly edited the map to influence the outcome.
Human committees have conflicts of interest. Token-based voting systems like UMA have whale problems and credibility issues when large holders vote on contracts they've bet on — even if they vote fairly, the optics undermine trust.
Thus, as any good VC would, a16z proposes to bring AI in. As mentioned, their idea is, at contract creation, a specific LLM and prompt would be locked into the blockchain. Traders could inspect the full resolution mechanism before betting — the model, the prompt, the information sources. If they don't like the setup, they don't trade. At resolution, the committed model runs with the committed prompt and produces a judgment. No rule changes mid-flight, no discretionary calls.
The benefits are real. LLMs resist manipulation better than human committees — you can't easily bribe a model or edit its weights after commitment. They're transparent in a way governance can't match. And they have no financial stake in outcomes, eliminating the conflict-of-interest problem that plagues token voting. To be clear, a16z isn't proposing to remove humans entirely — they acknowledge the need for ongoing governance around which models to trust, how to handle obvious errors, and when to update defaults.
But here's where the proposal runs into trouble.
The Reproducibility Gap
Run the same prompt through any major model with identical settings and you'll get different outputs. This is how modern inference works.
Why? It comes down to how GPUs process information. When you run a model, thousands of calculations happen simultaneously. The order those calculations finish in can vary slightly each time, and those tiny variations compound into different final outputs. We've all witnessed this and for chatbots it's irrelevant. It doesn't matter if your article summary is slightly different each time. If anything, it provides breadth. But for determining who gets paid on a $200M market, that's obviously a different story. In theory, the losing party could re-run the exact same prompt and get the opposite answer.
Now what?
The a16z proposal assumes that locking a model and prompt produces verifiable, auditable resolution. But if someone disputes the outcome and re-runs the same model with the same inputs, they might get a different result and, if the markets mentioned above tell us anything, it's that slight nuances can have significant impact.
As a result, the "transparency" benefit of adding AI evaporates because there's no canonical answer to audit against.
EigenAI's Deterministic Inference
This week, EigenAI published a whitepaper claiming bit-exact reproducibility on production GPUs: 100% match rate across 10K test runs, with minimal slowdown to inference speed.
How they achieve it comes down to controlling every layer of the stack — locking down all the places where variability creeps in.
At the hardware layer, anyone running or verifying inference must use identical GPU models. Since different chip architectures produce different results for the same calculations, even when running the same code, standardizing hardware becomes the first requirement.
At the software layer, Eigen replaces the default math libraries that GPUs use to run calculations with custom versions that enforce strict ordering. The default libraries prioritize speed over consistency; EigenAI's versions sacrifice a small amount of performance to guarantee identical outputs every time.
The result: given identical inputs, the output is a pure function. Run it a thousand times, get identical results.
To make this useful for prediction markets or any disputed AI output, EigenAI pairs deterministic inference with a verification system. Their model borrows from blockchain rollups. The party running inference publishes encrypted results. Results are accepted by default but can be challenged during a dispute window. If challenged, independent verifiers re-execute inside secure hardware enclaves. Because execution is deterministic, verification becomes simple: do the results match?
If they don’t, the mismatch will trigger slashing — economic penalties drawn from bonded stake. The original party loses money; the challenger and verifiers get paid. Privacy stays intact throughout: prompts remain encrypted, with decryption only happening inside verified secure environments during disputes.
Where Else This Matters
Prediction markets are the clearest use case, but they're not the only one.
ERC-8004 launched Thursday, bringing its first two registries, Identity and Reputation, online. The third, the Validation Registry that will coordinate third-party verification of agent work, is still under development but coming soon.
The Validation Registry is designed to be flexible. It will support multiple verification methods: ZK proofs, TEE attestation, human judges, or stake-secured re-execution where validators reproduce a computation and compare outputs. The registry itself is just a coordination layer — it records that a validator checked something and what they concluded, without mandating how they reached that conclusion.

For most of these methods, reproducibility is irrelevant. ZK proofs verify that a computation was performed correctly without re-running it. TEE attestation proves that specific code ran in a secure environment. Neither requires the underlying inference to be deterministic.
That said, for high-stakes operations — an agent managing significant capital, for instance — re-execution-based validation could add an extra layer of assurance. In those cases, builders would hit the same wall as prediction markets: without deterministic inference, you can't distinguish between an agent that “cheated” and one that simply got a different result from non-deterministic execution.
Solutions like EigenAI's would slot in here, enabling re-execution-based validation as one option among many. It's not a requirement for ERC-8004 to function, but for certain use cases, it could matter.
The Emerging Pattern
Overall, a16z’s idea of LLM judges is sound — transparent, neutral, resistant to manipulation. But without reproducibility, the proposal lacks the verification layer that would make it trustworthy at scale.
EigenAI's whitepaper suggests this gap is solvable. Deterministic inference is achievable with the right constraints: standardized hardware, custom libraries, controlled execution environments. The tradeoffs are manageable — a small performance hit for the ability to actually audit what an AI did.
For prediction markets specifically, this could solve one of its core issues. Lock in not just the model and prompt, but the infrastructure guaranteeing that anyone can re-run the resolution and get the same answer. Before we do that, though, it’s best to think twice about handing resolution over to the machines.
Plus, other news this week...
🤖 AI Crypto
📣 General News
- Anthropic — Launched interactive apps inside Claude, letting users run popular apps like Asana, Figma, Canva, etc. without leaving the chat, while also reportedly doubling its fundraising to $20B
- China — Alibaba open-sourced Z-Image, the full base of its top-ranked image model and released Qwen3-Max-Thinking, a new reasoning model competitive with all leading models. DeepSeek open-sourced OCR 2, a document text extraction model topping benchmarks with improved token efficiency
- Moonshot (also "China" but standout) — Open-sourced Kimi K2.5, its new model rivaling GPT-5.2 and Claude Opus 4.5 across coding, vision, and agentic benchmarks, as well as features Agent Swarm for managing up to 100 sub-agents, plus released Kimi Code, a terminal-based coding agent
- OpenAI — Reportedly building a social network and considering biometric verification like World's orb or Apple's Face ID to ensure users are human
- 🔥 OpenClaw — The open-source AI agent formerly known as Clawdbot rebranded twice after Anthropic flagged trademark concerns, now at 100K+ GitHub stars. Meanwhile, Moltbook launched as a Reddit-like social platform for AI agents — thousands of OpenClaw bots now post, debate, form communities, and discuss self-improvements
📚 Reads
- Auditless — AI Minimalism
- Castle Labs — USDai: Fuel for the Digital Age?
- 🔥 Dario Amodei — The Adolescence of Technology: Confronting and Overcoming the Risks of Powerful AI

Gold and silver are printing fresh highs. Ride the momentum on Bitget: trade 79 macro markets—commodities, forex, and indexes—directly with USDT. Diversify in one app with deep liquidity, low slippage, and up to 500x leverage to match different risk styles.
Not financial or tax advice. This newsletter is strictly educational and is not investment advice or a solicitation to buy or sell any assets or to make any financial decisions. This newsletter is not tax advice. Talk to your accountant. Do your own research.
Disclosure. From time-to-time I may add links in this newsletter to products I use. I may receive commission if you make a purchase through one of these links. Additionally, the Bankless writers hold crypto assets. See our investment disclosures here.